基于SOPC的PCI總線高速數(shù)據(jù)傳輸系統(tǒng)設(shè)計
點擊:1770
A+ A-
所屬頻道:新聞中心
隨著戰(zhàn)場電磁環(huán)境復(fù)雜程度越來越高,偵察與通信系統(tǒng)的融合成為一種必然的發(fā)展趨勢。數(shù)據(jù)量大、算法復(fù)雜是數(shù)字化偵察接收系統(tǒng)的主要特征。使用DSP和FPGA進(jìn)行高速信號譜分析、濾波等預(yù)處理,借助通用計算機平臺實現(xiàn)信號的分選、顯示等后處理是一種理想的系統(tǒng)設(shè)計方案。因此,如何構(gòu)建與PC機間的高速數(shù)據(jù)通道,便成了偵察接收系統(tǒng)設(shè)計中的關(guān)鍵問題之一。PCI (Peripheral CompONent Interconnect)總線,即外圍部件互連總線,是目前應(yīng)用最廣泛的一種高速同步總線,在32位總線寬度33Mz時鐘下,其理論最大傳輸速率可達(dá)132Mbyte/s (64位總線寬度66MHz時可達(dá)到528Mbyte/s),因此成為上述偵察接收系統(tǒng)中高傳輸速率、低成本PC接口的首選實現(xiàn)方式。目前,實現(xiàn)PCI總線接口的常用方法有兩種:一是采用專門的PCI橋芯片實現(xiàn)PCI接口,如PLX公司的PCI905X系列芯片等;二是使用可編程芯片實現(xiàn)PCI接口。
隨著集成電路技術(shù)的發(fā)展,可編程芯片成本越來越低、資源越來越豐富,用戶可將PCI橋和其它用戶邏輯在一片可編程芯片上實現(xiàn),其中后者不需要額外的PCI橋芯片,系統(tǒng)硬件電路得以簡化,系統(tǒng)的穩(wěn)定性和可靠性更高,進(jìn)而可以縮短系統(tǒng)開發(fā)周期。基于以上考慮,本文提出一種采用可編程片上系統(tǒng)(SySTem-On-Programmable-Chip,SOPC)實現(xiàn)偵察接收機PCI總線高速數(shù)據(jù)傳輸系統(tǒng)的設(shè)計方案,并采用直接存儲器訪問(DIRect Memory Access,DMA)傳輸方式來提高數(shù)據(jù)傳輸速率。
1 PCI總線接口方案設(shè)計
在PCI總線接口標(biāo)準(zhǔn)中,根據(jù)數(shù)據(jù)傳輸?shù)陌l(fā)起者所在位置,PCI接口有從模式和主模式兩種工作模式。根據(jù)工作方式的不同,DMA傳輸方式可分為連續(xù)式DMA (Continuous DMA)和集散式DMA(Scatter-Gather DMA)兩種。
1.1 PCI模式的選擇
PCI總線標(biāo)準(zhǔn)中,由PC發(fā)起數(shù)據(jù)傳輸、讀/寫PCI接口卡的模式稱為從模式。這種模式只要求PCI接口設(shè)備具備PCI從設(shè)備的功能,接口邏輯相對較簡單;主模式是由PCI接口卡主動讀寫PC內(nèi)存,PCI接口的邏輯相對復(fù)雜。頻繁地要求PC發(fā)起數(shù)據(jù)傳輸會占用PC的資源,為了減少PC的負(fù)擔(dān),使其有更多的資源用于后續(xù)的數(shù)字信號處理,在偵察接收系統(tǒng)中,PCI接口卡的傳輸模式選擇主傳輸模式。
1.2 DMA傳輸方式的選擇
DMA是提高數(shù)據(jù)傳輸速率和微處理器使用效率的一種數(shù)據(jù)傳輸機制。連續(xù)式DMA用于實現(xiàn)連續(xù)數(shù)據(jù)塊的傳輸,即在一次DMA傳輸中設(shè)備端讀/寫物理地址連續(xù)變化(讀存儲器空間)或不變化(讀IO口),PC端的物理存儲地址連續(xù)變化。集散式DMA用于實現(xiàn)不連續(xù)數(shù)據(jù)塊的傳輸,各傳輸數(shù)據(jù)塊的起始讀/寫地址和長度都可以不同,它采用一個寄存器鏈表存儲每個數(shù)據(jù)塊的讀/寫起始地址和長度,DMA傳輸過程中自動從該鏈表加載地址和長度信息。集散模式DMA應(yīng)用靈活,其缺點是在傳輸完一個數(shù)據(jù)塊之后要重新配置DMA控制寄存器的值,速度比連續(xù)模式稍慢。在偵察接收系統(tǒng)中,DMA傳輸模式選擇連續(xù)式傳輸模式。
1.3 PCI總線DMA傳輸方案設(shè)計
PCI接口總體結(jié)構(gòu)框圖如圖1所示。數(shù)據(jù)輸入到乒乓RAM緩沖區(qū),乒乓切換信號通知CPU數(shù)據(jù)準(zhǔn)備好,CPU通過PCI橋的控制狀態(tài)寄存器判斷PC端是否備妥,如PC備妥則配置并啟動DMA控制器,DMA控制器讀口從乒乓RAM中讀數(shù)據(jù),寫口將數(shù)據(jù)寫至PCI總線訪問端,PCI總線接口單元申請并獲得PCI總線訪問權(quán),將數(shù)據(jù)送上PCI總線。
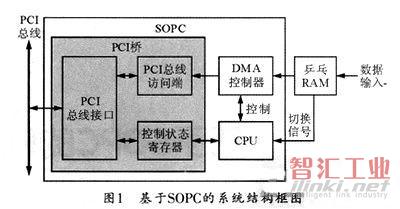
2 PCI總線接口的SOPC實現(xiàn)
SOPC是Ahera公司提出的一種靈活、高效的片上系統(tǒng)解決方案,它將處理器、存儲器、I/O口以及一些通用的功能模塊集成在一個PLD器件上,構(gòu)成一個可編程的片上系統(tǒng)。利用SOPC開發(fā)偵察接收機中的PCI總線接口,具有開發(fā)周期短、系統(tǒng)穩(wěn)定性好的優(yōu)點。
2.1 系統(tǒng)實現(xiàn)
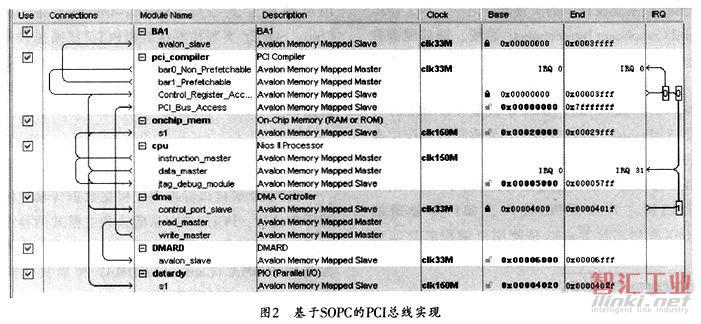
PCI總線接口的SOPC內(nèi)部結(jié)構(gòu)如圖2所示。實現(xiàn)PCI總線DMA傳輸系統(tǒng)使用到4類功能模塊,分別是實現(xiàn)PCI橋邏輯的pci_comiler組件(pci_c ompiler)、負(fù)責(zé)數(shù)據(jù)傳輸?shù)腄MA控制器(dma)、控制整個SOPC的NiosII處理器(cpu)及其數(shù)據(jù)程序存儲器(onchip_mem),以及SOPC和外部用戶邏輯通信的接口模塊(BA1、DMARD和datardy),上述組件通過avalon總線連接在一起組成SOPC。
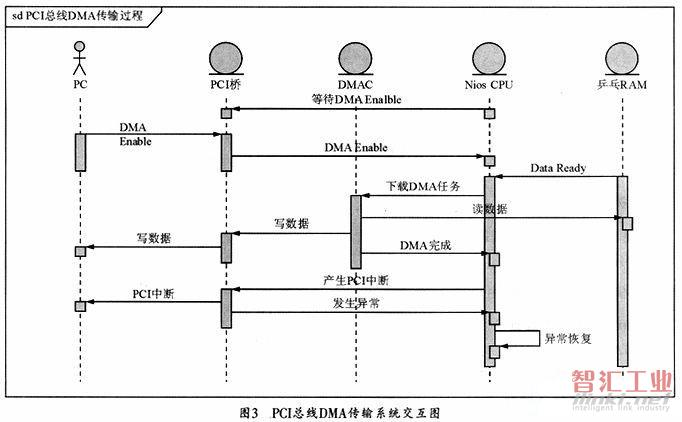
PCI總線DMA傳輸系統(tǒng)功能模塊之間的交互過程如圖3所示,過程描述如下:
(1)CPU等待PC使能DMA傳輸,PC使能DMA后,執(zhí)行(2);
(2)PC等待乒乓RAM的數(shù)據(jù)準(zhǔn)備好信號,數(shù)據(jù)準(zhǔn)備好后,執(zhí)行(3);
(3) CPU將DMA的讀/寫地址和傳輸長度參數(shù)寫入DMA控制器中,使能DMA控制器,DMA控制器開始數(shù)據(jù)傳輸,即讀口通過DMARD接口從RAM中讀數(shù),寫口將數(shù)據(jù)寫到PCI橋,PCI橋?qū)?shù)據(jù)送至PCI總線;
(4)當(dāng)傳輸結(jié)束后,DMA控制器產(chǎn)生一個中斷(IRQ1)送CPU;
(5)CPU判斷傳輸是否完成,傳輸完成則通過PCI橋向PC發(fā)送中斷,并執(zhí)行(1),開始下一次DMA傳輸;
(6)PCI總線發(fā)生異常時,PCI橋邏輯中斷CPU,CPU查詢異常狀態(tài),并自動從異常中恢復(fù)。
2.2 PCI總線異常的自動處理
PCI總線DMA傳輸過程中,可能出現(xiàn)的異常包括:
(1)PCI總線上SERR信號為高,系統(tǒng)錯誤。
(2)PCI總線上PERR信號為高,數(shù)據(jù)奇偶校驗錯誤;
(3)主設(shè)備或從設(shè)備中止傳輸;
(4)主設(shè)備或從設(shè)備中止傳輸,或重試次數(shù)超過門限,導(dǎo)致PCI橋?qū)偩€讀/寫失敗。
在偵察接收系統(tǒng)設(shè)計中,上述異常一旦發(fā)生,PCI接口便中斷NiosCPU,CPU接收到中斷后,通過查詢PCI橋的控制寄存器訪問(Control RegisterAccess,CRA)空間,獲得異常信息。系統(tǒng)錯誤發(fā)生時,PCI接口設(shè)備是沒有辦法恢復(fù)的,在這種情況下,NiosCPU可點亮指示燈,指示系統(tǒng)錯誤發(fā)生;其它異常情況發(fā)生后,Nios CPU可立即通過對DMA控制器的狀態(tài)空間的長度寫零來停止DMA傳輸,然后重新啟動DMA傳輸,讓系統(tǒng)從異常中恢復(fù)過來。
2.3 提高PCI總線DMA速率的優(yōu)化措施
為了盡可能提高DMA傳輸速率,本方案中共采取了以下三個方面的措施。
(1)PCI總線的突發(fā)傳輸與Avalon總線的流水線操作
為了提高系統(tǒng)傳輸速率,應(yīng)充分利用PCI總線的突發(fā)傳輸特性,使PCI總線處于突發(fā)傳輸狀態(tài)。為此,在系統(tǒng)設(shè)計中,一方面使Avalon總線工作于流水線模式下,降低Avalon總線的延遲時間;另一方面適當(dāng)增大緩存存儲空間,避免因緩沖區(qū)滿造成的傳輸延遲等待。
(2)DMA控制的優(yōu)化
為了使DMA傳輸更為靈活,如程序運行過程中改變DMA長度、讀寫地址、數(shù)據(jù)的幀長度,以及發(fā)生異常時程序自動恢復(fù)等,本文中使用Nio sCPU控制DMA傳輸。CPU的主要任務(wù)是在PC使能DMA和數(shù)據(jù)準(zhǔn)備好時啟動DMA傳輸,應(yīng)盡可能使程序緊湊,減少冗余操作,做到條件具備立即啟動DMA傳輸。
(3)功能模塊的時鐘設(shè)置
如圖2所示,SOPC中包括7個功能組件,為了進(jìn)一步提高系統(tǒng)的速度,需要分別讓這7個組件的時鐘處于最佳狀態(tài)。PCI總線訪問相關(guān)組件的時鐘為33MHz,Nios CPU相關(guān)的組件運行在150MHz時鐘上。使系統(tǒng)在正確穩(wěn)定運行的基礎(chǔ)上,最大限度地提高運行速度。
3 結(jié)束語
本文給出了一種基于SOPC系統(tǒng)的PCI總線高速DMA傳輸方案。與傳統(tǒng)的使用PCI橋芯片實現(xiàn)PCI總線的方案相比,該方案將PCI橋和用戶邏輯在一片F(xiàn)PGA中實現(xiàn),減少了硬件電路的復(fù)雜度、降低了系統(tǒng)成本;采用SOPC創(chuàng)建PCI橋,大大縮短了開發(fā)周期,提高了系統(tǒng)的可靠性,且因使用了片上Nios CPU進(jìn)行DMA的在線配置和自動異常處理,使DMA傳輸更加靈活。通過在EP3C120芯片上驗證,該設(shè)計能夠?qū)崿F(xiàn)大于100Mbytes /s的PCI總線DMA傳輸速率。
(審核編輯: 智匯胡妮)
分享
品專題")
升級")

